How to adopt Code Security at Enterprise Scale
Disclaimer: The views expressed in this blog post are fully my own.
From my experience advising and accompanying large enterprises in rolling out Code Security for up to 7,000 developers (both at SonarQube and recently at GitHub), I can tell two things: that by now, we all realize why securing an enterprise codebase is critical and that the task remains a challenge to most.
Vulnerabilities in the code may let attackers gain access to sensitive data and systems, while credentials inadvertently or naively written down into code files may allow them to do the same in an even easier way. Some examples of large attacks involving insecure code include this one for TikTok, this other one affecting Wordpress plugins and the infamous log4j dependency vulnerability, which is still being exploited.
While there are a myriad of tools available to secure an enterprise’ source code, there are still some very real barriers to adopting code security at scale:
Detecting security issues in code usually requires configuring scanner tools, which are complex to set up at scale.
Preventing security issues from slipping into code in the first place requires detection to be set up first, and an agreement between leaders, at least from engineering and security orgs, including on when exceptions may be allowed.
Remediating the existing, detected security issues may provetoo big of a task to tackle, with any fixes adding to the risk of regression.
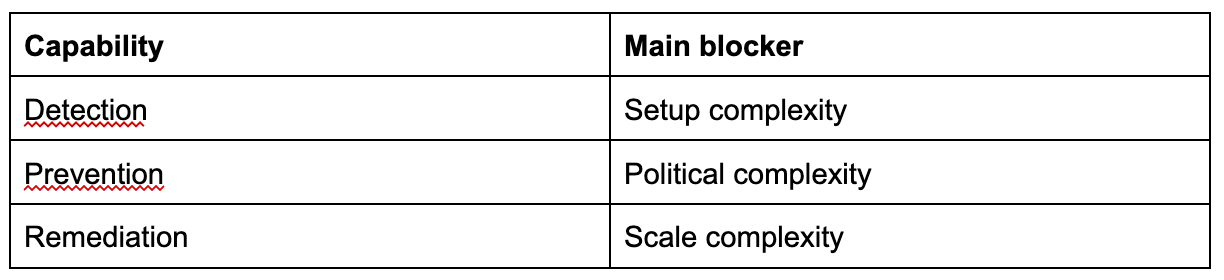
It is paradoxical that most organizations focus primarily on setting up detection, while neglecting or being unable to significantly progress into prevention and remediation. These two capabilities have a net impact on the security posture of the organization and thus bring a return on the investment in the code security tool of your choice.
For most of the last 5 years in my career this has been the constant challenge I’ve helped companies solve. And in this blog post, I‘ll share with you the key lessons I’ve learned with the most effective strategies, which you can immediately apply regardless of your tooling. I’ll accompany this with a concrete example on reaching optimal Code Security with GitHub Advanced Security at enterprise scale.
Code Security Rollout Strategy: guiding principles
At the core of the strategy I’ll present to you lies a very basic principle: realizing the full business value of code security at a small scale as quickly as possible (demonstrating ROI) and building up from there. So where do we find this value in code security tooling? In functionalities that clearly help the organization prevent and remediate code security issues.
In essence, when it comes to code security, you need to detect your current security issues, remediate them and prevent new ones from making it into your code. While detection gives you useful information about your exposure to cyberattacks, it does not change the likelihood for these attacks to succeed. Detection is a necessary step, but it is not going to realize any value for the business by itself. It is prevention which will avoid increasing your exposure to attacks, and it is remediationwhich will reduce your current exposure to security incidents.

You may excel at detection, but if you do not use that information to stop your security posture from worsening and reducing it, there is no return on the investment into a code security tool. And if there is no quick return, the tool will lose internal support and stall or be replaced. If you agree with this, then it’s easy to see why any rollout strategy should not focus solely on detection, nor on achieving full detection across the enterprise codebase before moving to preventing and remediating issues.
The most successful code security rollout strategy I’ve put together followed these 4 steps:
Building up detection capabilities on a subset of the enterprise codebase
Quickly implementing prevention measures on the chosen subset
Kicking-off remediation campaigns on the subset
Move to the next codebase subset and repeat
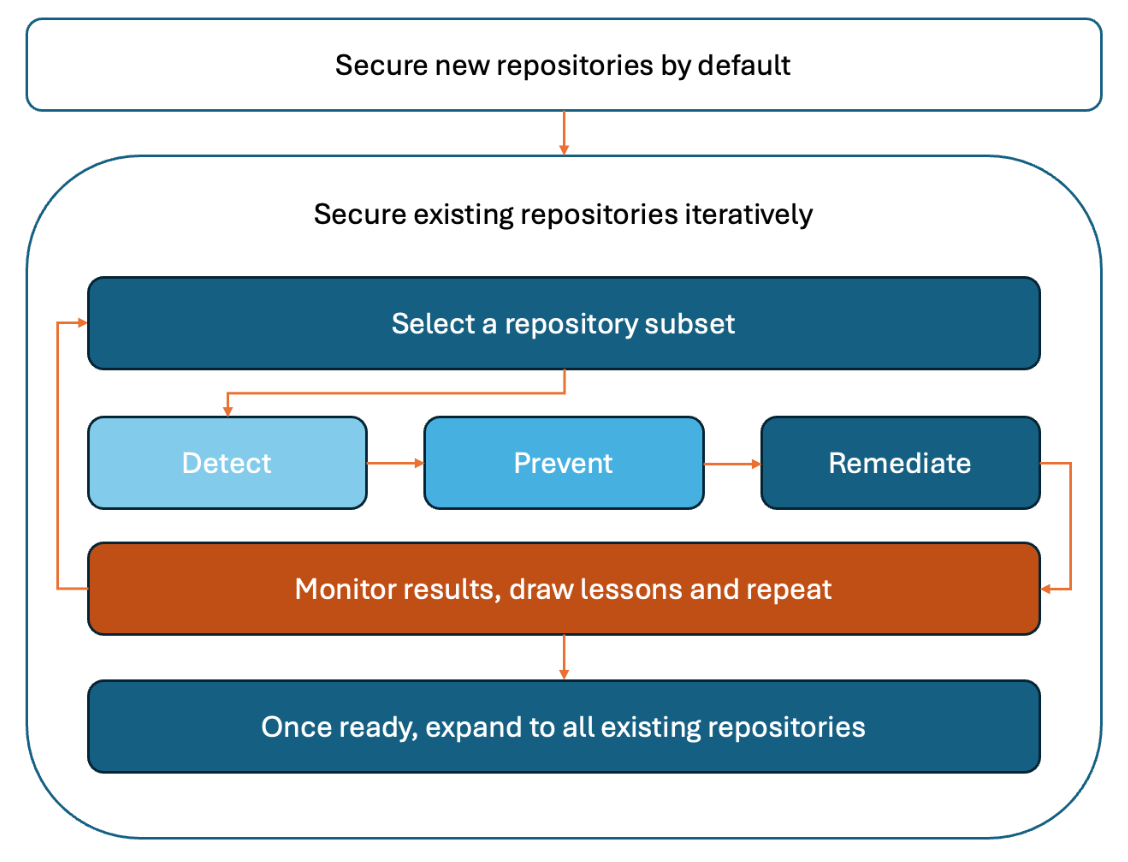
All along the implementation of this strategy, monitoring the efforts and their results is the last important component. This will give you data to demonstrate tangible success and gain additional internal support to move to yet securing a larger codebase.
And that’s it, those are the guiding principles. Now of course, we need to deal with the implementation details, which will differ from one enterprise to another and one tool to another.
Rolling out GitHub Advanced Security at enterprise scale
Note: written in December 2024, product functionality quickly evolves and this post may not.
Here, I will focus on GitHub Advanced Security, which is the tool I work with every day. Remember that most of the functionality is available for Open Source, public repositories.
Secure new repositories by default
This step may come right at the very beginning of your journey if you have internal support within your Organization. If not, you should delay this until you’ve got it. Whenever you are ready, you need to make sure that any new repository that’s created in your GitHub Enterprise is set up with security by default.
To do that, make sure to use the GitHub Recommended Security Configuration (or create a custom one) at Enterprise Level, and edit it to define it as the “default for newly created repositories”. Additionally, you should probably enforce it to avoid repository admins from being able to disable such security settings. Click save, and you are ready to go.

Secure existing repositories iteratively
Let’s go through the activities needed to fully secure existing repositories in GitHub. I’ll follow the flow I shared in the diagram above.
1. Select a Repository Subset
You need to be thoughtful about the strategy around selecting the initial repository subset to secure. If you are on your first iteration, and you work in a very large business, I would advise against selecting the largest, most complex repositories. With the aim of demonstrating ROI quickly and gaining internal support, it’s best to start with simple repositories operated by agile and innovative teams willing to collaborate.
Once you’ve made your choice, the easiest way to target your repositories will be creating and setting up Repository Custom Properties. For example, you may define a custom boolean property called “ghas-secured” and set it to true on your target repositories. This will allow us to easily set up detection, prevention and running remediation on those specific repositories. You can set these up at either Enterprise or Organization level.
2. Setup Detection
Now it’s time to set up detection of security issues in your selected repositories. GitHub Advanced Security detects 3 types of security issues:
Leaked secrets in your repositories (through the code or through GitHub discussions, issues and PRs)
Vulnerabilities in OSS dependencies of your repositories
Vulnerabilities in code committed into your repositories
To detect all of these, you need to set up a Security Configuration and apply it to your target repositories based on the custom property value you had set up in the previous step. The security configuration needs to be configured with Secret Scanning, Dependabot Alerts, and Code Scanning with “Default Setup” as a minimum. You may also choose the default security configuration provided by GitHub and apply it directly to your repo subset - it already comes pre configured with those minimums.
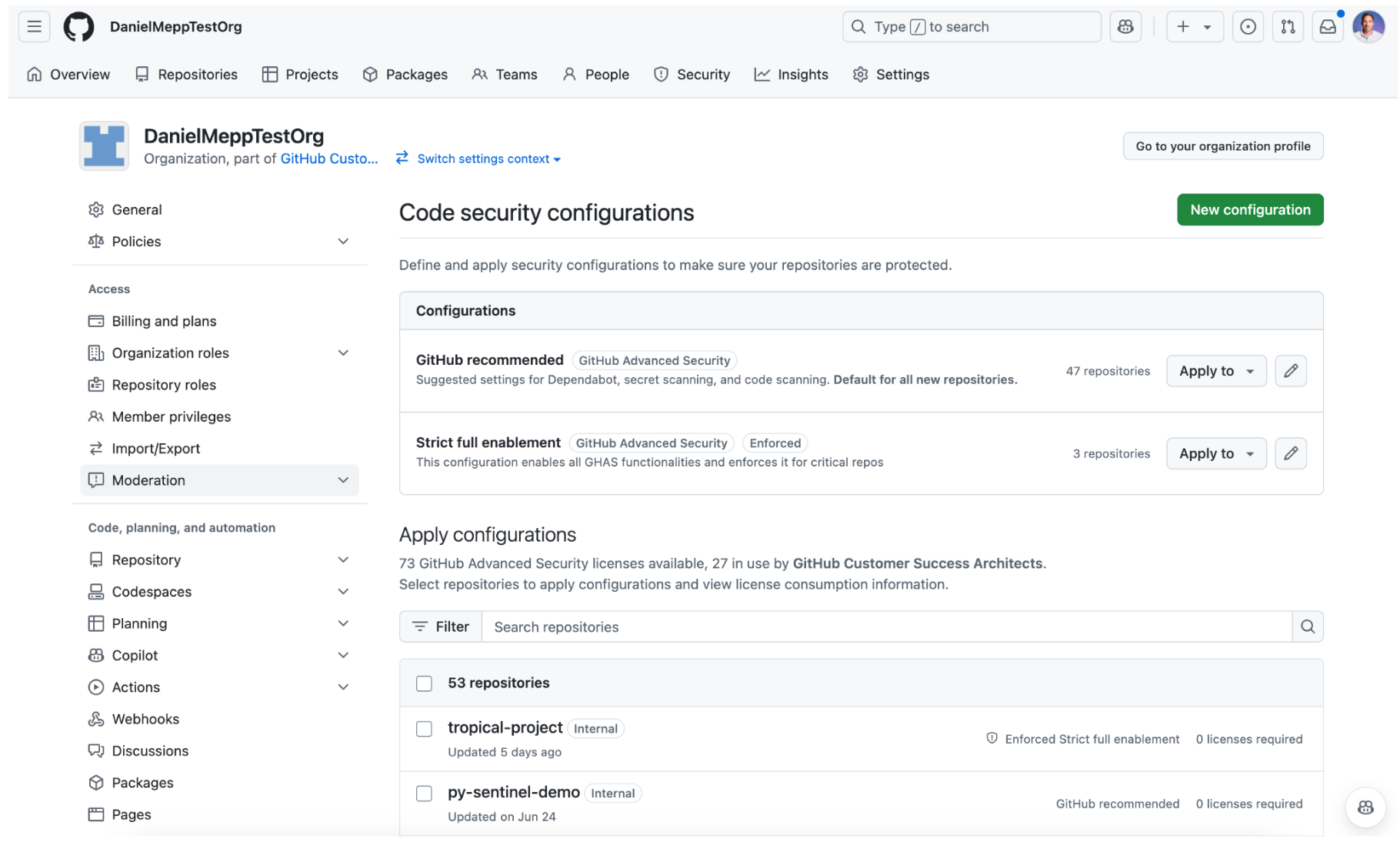
This is already great but it won’t scan your Pull Requests looking for vulnerable OSS dependencies there - which is needed to establish proper prevention later on. To do this, you need to set up a mandatory Dependency Review required workflow leveraging Rulesets. You can store this workflow on any repository. Here is a yaml GitHub Actions workflow example:
name: 'Dependency Review'
on: [pull_request]
permissions:
contents: read
jobs:
dependency-review:
runs-on: ubuntu-latest
steps:
- name: 'Checkout Repository'
uses: actions/checkout@v4
- name: Dependency Review
uses: actions/dependency-review-action@v4
with:
# Possible values: "critical", "high", "moderate", "low"
fail-on-severity: criticalThe important bit is the fail-on-severity flag, which should fail when finding critical vulnerabilities in dependencies added through any PR, as a minimum. Store the workflow, which we will use when setting up prevention.
3. Setup Prevention
You now need to make sure that new code pushed to the repository does not add new security issues. We will set up prevention for the three types of security issues again (secrets, dependencies and authored code).
Whatever Security Configuration you had applied, you need to make sure you enabled Push Protection for Secret Scanning on it. If you applied GitHub’s recommended Security Configuration, this setting is already enabled. This will prevent anyone from pushing secrets to repositories, effectively avoiding leaks and the remediation/secret rotation effort that comes with it.
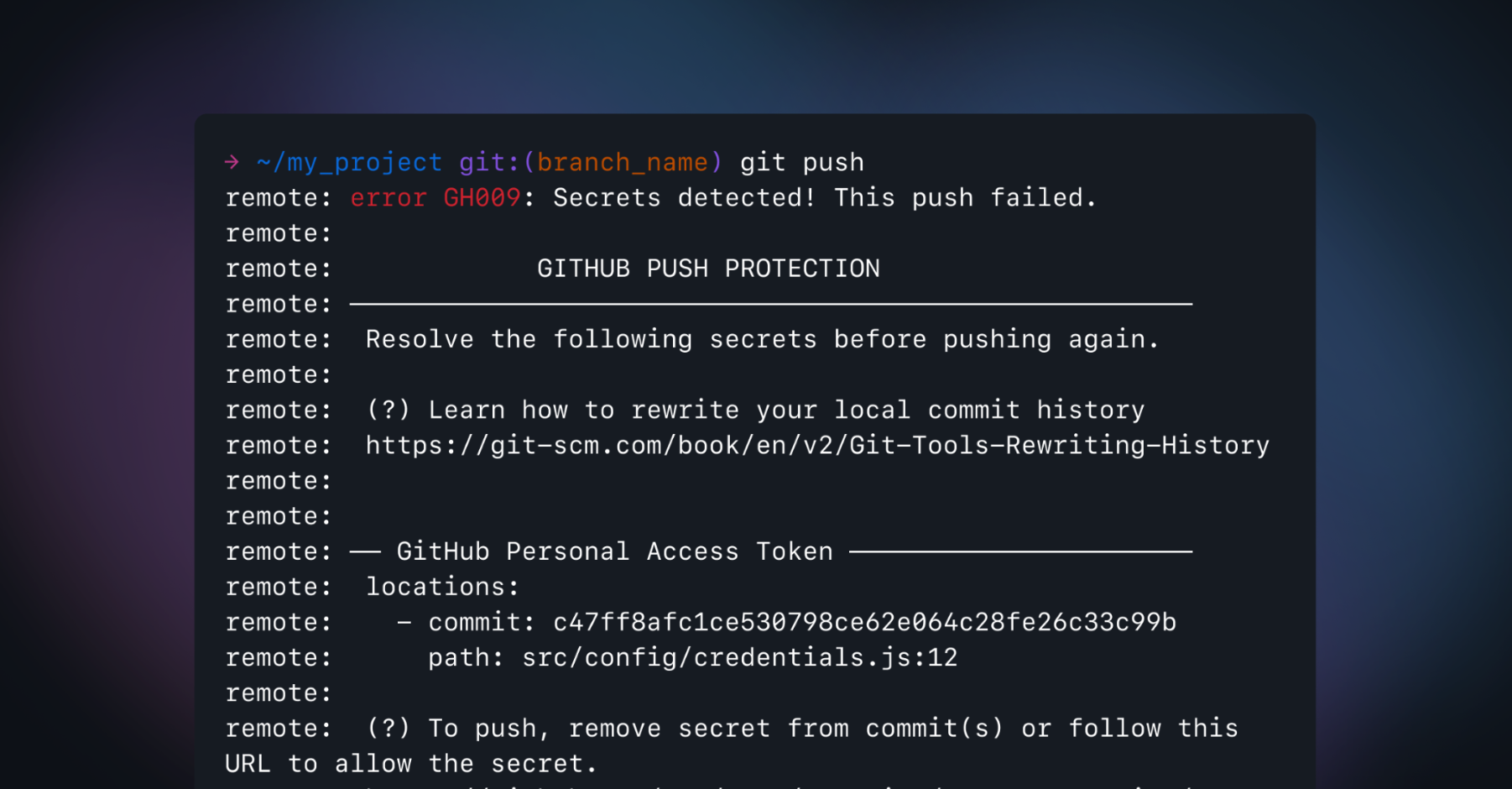
When it comes to dependencies, we will leverage the dependency review workflow you created in the previous step. Configure an Organization level repository ruleset that requires pull requests before merging and mandates the dependency review workflow to pass on your target repositories’ protected branches (or at least the default branch of the repository). You can use the custom property you previously set on your repo subset to target them in the ruleset. For now, you need to create this ruleset on each Organization where you have repositories to secure, but I hope this will become easier soon (you can at least export and then import the ruleset on each Organization).
In contrast to Dependency Review, Rulesets offer a specific rule to make CodeQL mandatory. In order to make CodeQL mandatory on any Pull Request targeting protected branches of your repositories, we can use the same rulesets you just created to mandate Dependency Review. You’ll simply check the box to require code scanning results with CodeQL. Alternatively, if you have many Organizations, you can make CodeQL scanning mandatory for PRs at the Enterprise level.
Remember that PRs blocked by any of these rules, including Secret Scanning push protection, can still be merged if you setup bypass rules as well as delegated bypass for push protection. This is handy to avoid situations where it is time-critical to ship a change in code, despite it containing potential security issues.
4. Run Remediation
Now that you have detected security issues in your repository subset, you can kick-off an initial, small and highly targeted effort to remediate them.
You should design and launch a Security Campaign targeting found vulnerabilities, starting from the higher severity ones. You need to involve the engineering leadership responsible for the repositories you are targeting in order to co-create the campaign with them and gain their support to make it a success.
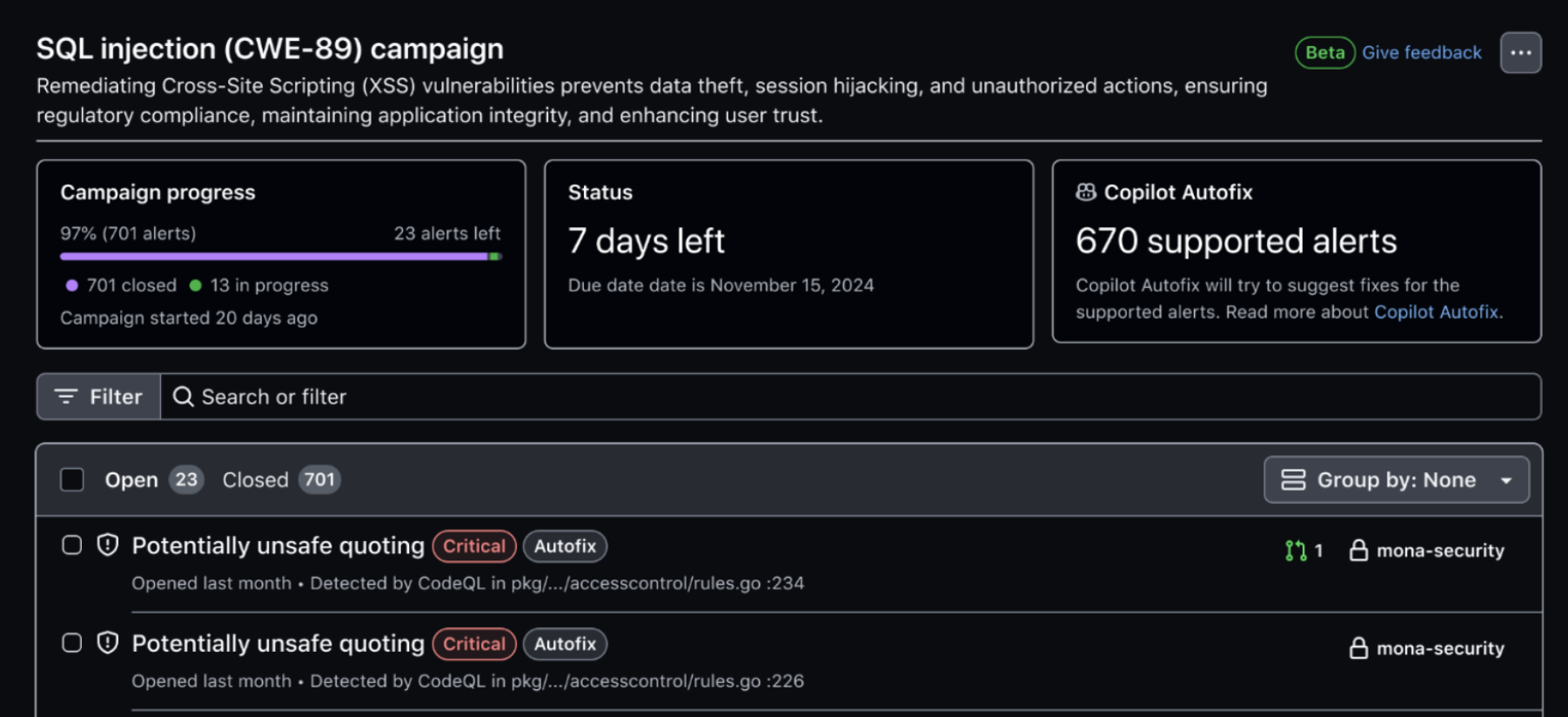
Once the campaign has launched, your developers may take advantage of GitHub Copilot Autofix responsibly to speed up the remediation effort.
5. Monitor, learn and repeat
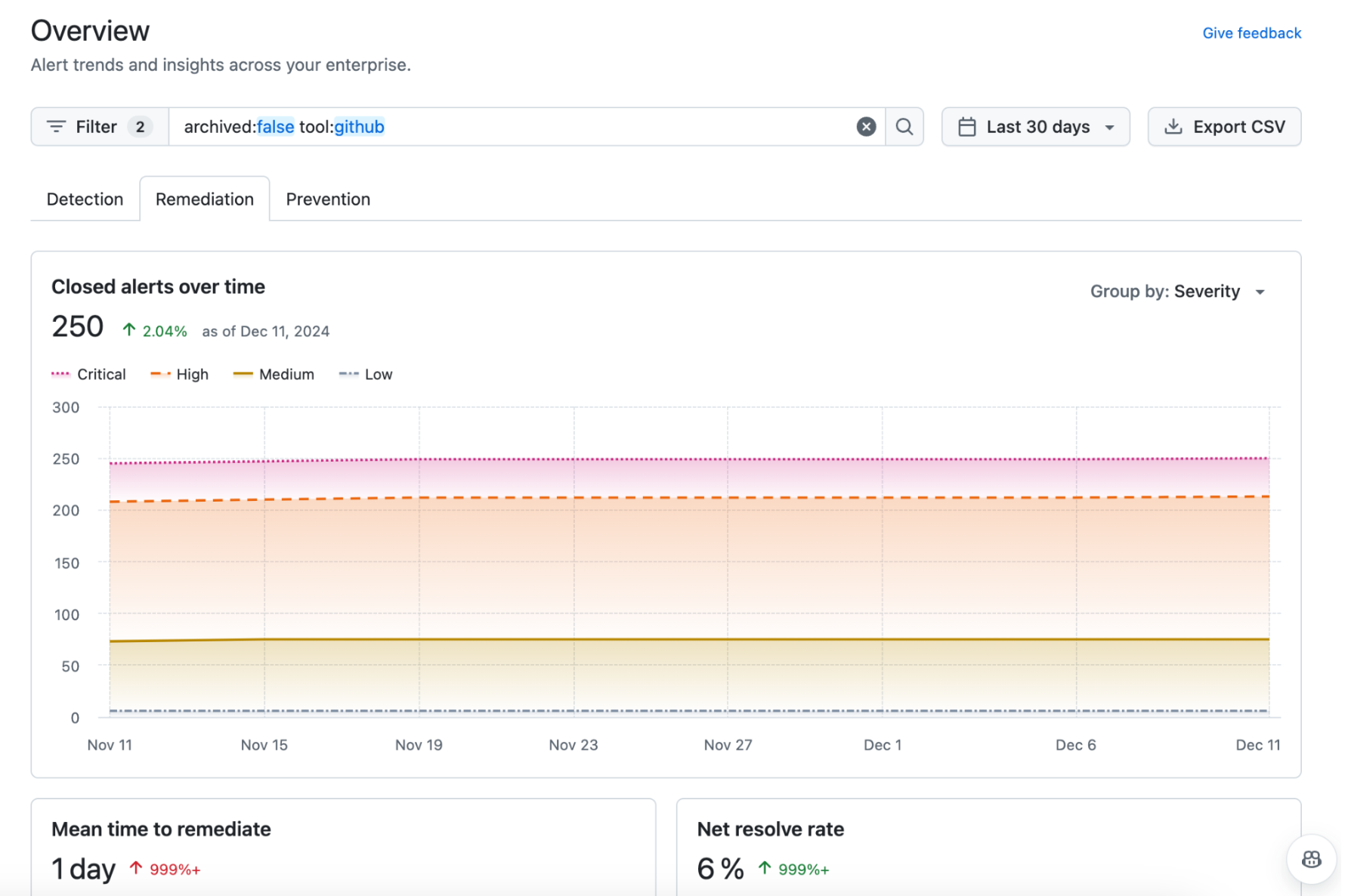
Your first iteration shall be the exercise that fully realizes the value of the Code Security tool of your choice, demonstrating clear return on your investment. You need to track progress on prevention and remediation (as well as on detection, for coverage/operational reasons) and quantify such ROI using metrics attached to those efforts such as secret leaks blocked and security alerts remediated.
If you use GitHub, you can do that with the Security Overview dashboard. As you can see below, it contains three tabs directly linked to the key capabilities I discussed (detection, prevention and remediation).
6. Expand to all repositories
You need to iterate over the steps above until you get the internal support and alignment needed to expand to all the repositories of your enterprise. Once you can do that, you simply need to scale the Security Configurations you had created and/or create new ones leveraging Repository Custom Properties as needed. This will give you a lot of flexibility to apply different settings to different repository subsets if required.
Summary
This is a general guideline and specific, relatively simple example, but gives you the notions to most likely, adapt and apply them at your enterprise. As Code Security tooling improves, I expect each step of the process to become more seamless and simple. Specially with AI proving its value already in many security areas, like automated fixes, I expect it to help with detection setup for complex projects. And as the industry convenes on the criticality of securing code, I expect this tooling to become a fundamental, inseparable piece of any solid development platform.
I hope this helps!
Thanks for reading.